Use BPFJIT to solve khash from n1CTF 2025
Exploit a(ny?) kernel UAF without leaking any address.
In short…
- N1khash has delayed work UAF, which contains a vtable.
- We do pgv spray to reclaim the UAF slot in kmalloc-256.
- We setup pgv content as (0xffffffffc1000000 - 0x800), which is basically a kernel one-gadget in our sprayed BPF JITed code.
- Wait for the delayed work been executed and wins, no need to do any leak.
The vulnerability
When opening /dev/khash, the module allocates a control structure in kmalloc-256 without any isolation: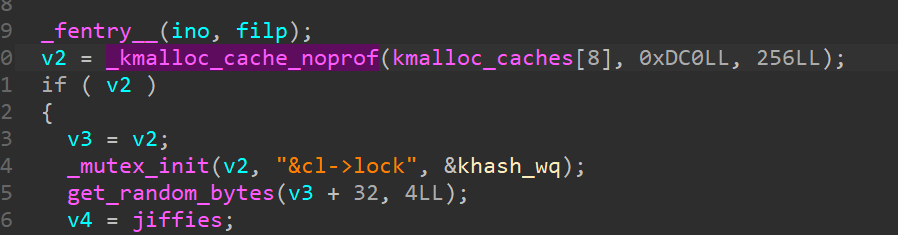
The khash can schedule delayed work, when the work is executed, it will invoke two functions from vtable inside the control structure:
(Both vtable[0] and vtable[1] will be called)
To queue a delayed, we can use 0x4010B110 ioctl:
If we close the fd before the delayed work is executed, the control structure will be freed and when the work is executed, it will get vtable from a freed kmalloc-256 chunk.
Exploit plan
From now on, we can already gain two free Control-Flow-Hijack primitives.
I have discussed what can we do with a pure CFH at my previous writeup about corCTF, but most of them at least require an kernel .text leak to perform ROP (panic_on_oops disable, RetSpill, NPerm or regular stack pivoting).
However this challenge has not enable kvm when booting the kernel, so it’s not trivial to bypass KASLR with hardware side channel.
We may certainly reverse the khash module more and see if there is any good info leak, but I decided to use Ret2BPF directly which does not require any info leak.
Thanks to the challenge author who provided the Kconfig so that we can quickly check
BPF_JITis enabled (which is so nice that we do not need to guess the kernel config once and once again).
And we can also seeSTATIC_USERMODE_HELPERis not set so our shellcode can be much simpler with just modifyingmodprobe_pathorcore_patterninstead of performing a ret2usr ortask_structsearch.
Also please note that unprivileged_bpf_disabled is not relevant with the cBPF spray in Ret2BPF, so we do not need to care about it.
Exploit! Exploit! Exploit!
Before we actually went to CFH, we need to prepare a structure belongs to kmalloc-256 which at 0x28 offset is a data pointer that the data it points to will be controlled by us.
I choose pgv array as a good candidate, since it will be a elastic array which every element is a pointer points to a shared memory which fully controlled by user.
1 | struct pgv { |
By using pgv[32] to reclaim freed khash control structure, we can setup the vtable and control the function pointer without any info leak.
Then the only thing left is to spray our cBPF program to get a JITed native code area, the allocation address of BPF JITed code is highly predictable and if we spray enough (0x600 programs with 0x900 length each in this exploit).
By simply setting the function pointer to 0xffffffffc1000000 - 0x800, we can jump to the middle of our sprayed BPF JITed code.
You can find more details about Ret2BPF in the original writeup and recent discussion.
Besides, if bpf_jit_harden is enabled, we can still use Ret2BPF with the enhanced version from kctf CVE-2025-21700 exploit.
Also, the enhanced version can achieve ~100% stability instead of 80%.
Since x86 is Variable-Length Instruction Set Architecture, we can spray LOAD CONSTANT instructions to load arbitrary 32-bit constant (without BPFJIT hardening). We can certainly jump to the middle of those 32-bit constants to trick CPU to interpret them as our shellcode.
The original Ret2BPF use 0xb3909090 as nop sled, so that the LOAD CONSTANT instruction 0xb8xxxxxx : (mov eax, 0xxxxxxxxx) can be interpreted as .. 90 b8 b3 90 90 90 (b8 b3 : mov bl).
At the end of the sled, we can place our 3-byte length shellcodes to do the actual privilege escalation.
So the main logic of exploit is:
1 | int main() { |
The full exploit code can be found at the end of this writeup.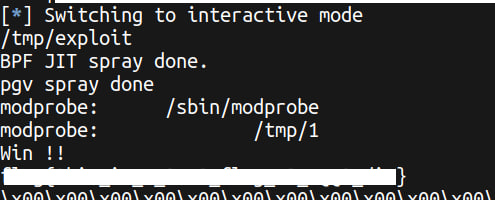
Misc notes
modprobe_path
This commit at about Linux 6.12 removed usage of binfmt so that executing a unknown binary format will not invoke modprobe anymore. But we can still use some unprivileged syscall to force kernel load more kernel modules (which is compiled but not loaded by default), such as:
1 | socket(AF_INET, SOCK_STREAM, 132); |
This trick is also been discussed and well studied in SyzBridge.
Shellcode
The original copy_from_user shellcode is good enough, but if we want to perform more complex operations in the shellcode, we can disable the WP bit and copy shellcode from user memory to kernel executable memory and then jump to it.
End of the Trail
After all those merciless 48h CTF events, it’s sweet to have a 24h CTF and enjoy the rest of weekend at beach 🥰
Full exploit code
1 |
|
Generate sc.h with the following python script:
1 | #!/usr/bin/env python3 |
Interactive with remote:
1 | import os, base64, gzip |
Use BPFJIT to solve khash from n1CTF 2025